LangGraph is part of the suite of LangChain offering.
LangGraph is a low-level orchestration framework and runtime for building, managing, and deploying long-running, stateful agents. (…) focused entirely on agent orchestration.1
You don’t need to use LangChain to use LangGraph1.
In order to create a flow in LangGraph, it is first important to map out the different states in which the processing of the request can happen. This is as easy as mapping out a decision workflow into different “steps” that might follow each other.
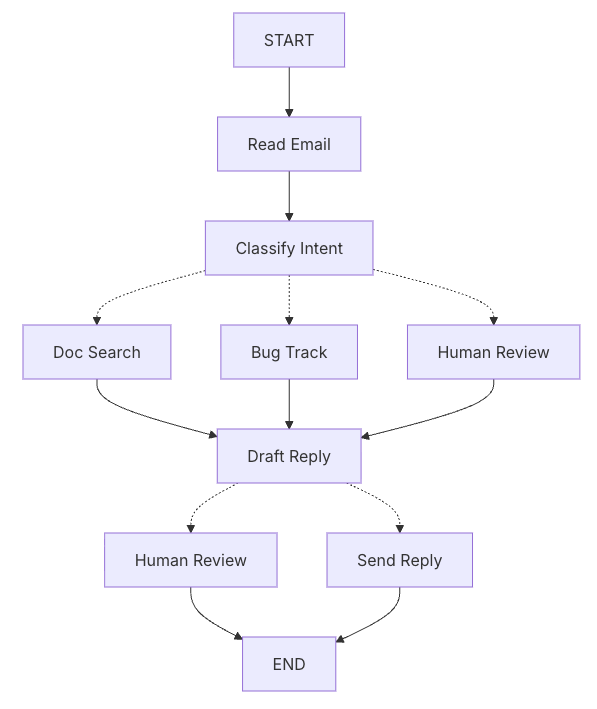
Each node can result in connecting to others, but the actual decision is carried out inside each node by the intelligence/tools provided into it.
Each of the nodes might be one of the following type of operation:
- LLM Steps: Understand, analyze, generate text or perform reasoning decisions
- Data Steps: Retrieve data from external sources
- Action Steps: Perform external actions
- User Input Steps: Request human intervention
The state is the shared memory accesible to all nodes in the agent. It is recommended that the state is stored in a raw format, while the formatting needed for specific nodes will be handled by the prompt required for those needs.
The state can be defined in structure by using Zod.
Each node is just a function that accepts the state and returns modifications to it.
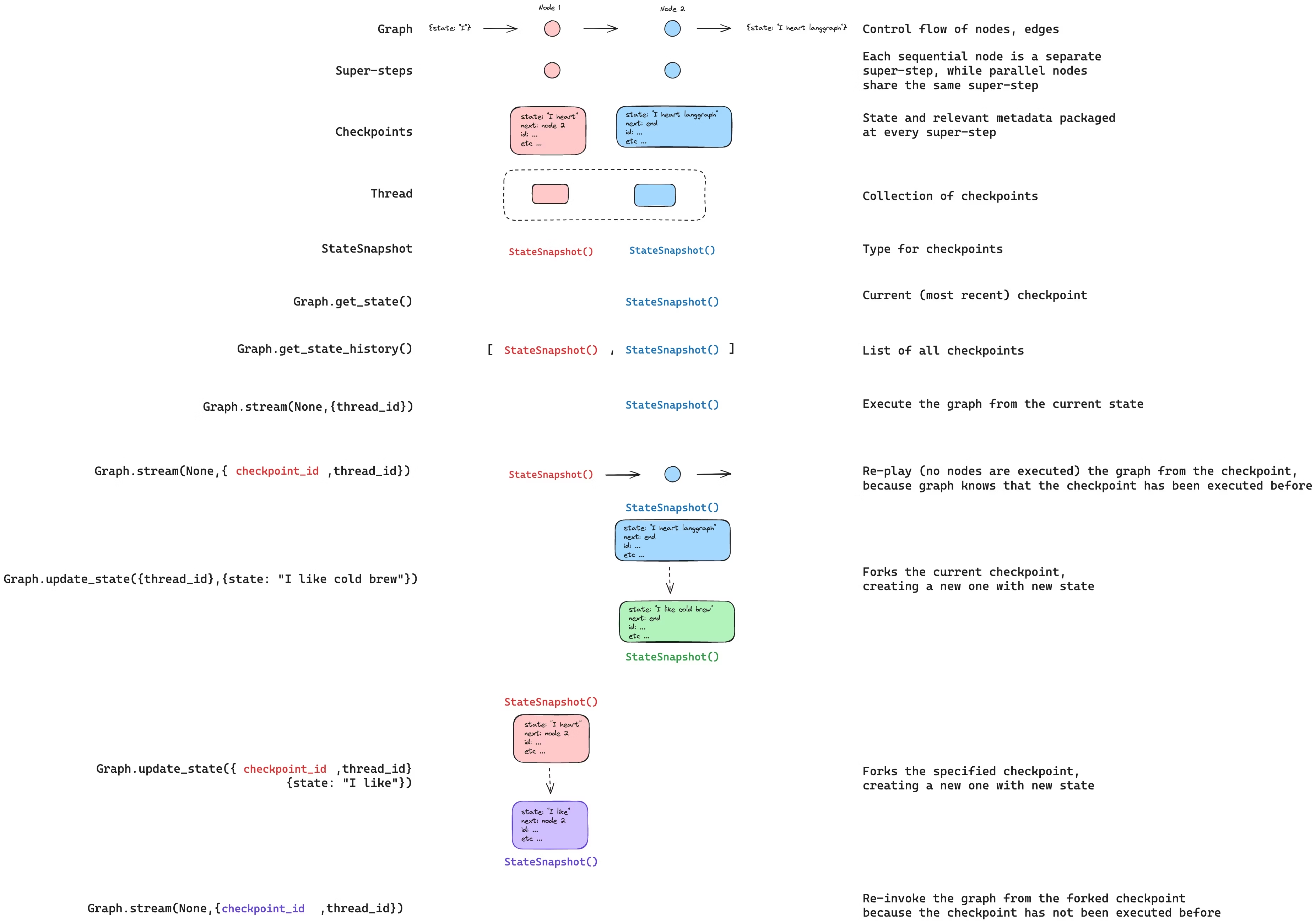
Persistence
LangGraph persistence layer is implemented through checkpointers, that store a checkpoint of the current graph execution state. Each checkpoint is saved to a thread, that can be accessed later on. A thread is a unique ID assigned to each checkpoint. Graphs that have checkpoints must be involved with a thread_id:
{
...
configurable: {
thread_id: "1"
}
}Each snapshot (represented by the StateSnapshot object per each super-step) has:
config: Configuration associated with the checkpointmetadata: Metadata associated with the checkpointvalues: Values of the state channels at this point in timenext: A tuple with the node names to execute next in the graphtasks: A tuple withPregelTaskobjects about next tasks to be executed
Checkpointers will automatically store the graph state in an async way as to not impact performance.
Snapshots and snapshot history for a graph can be retrieved by using the graph.getState(config) and graph.getStateHistory(config) methods.
Graphs can be invoked from a specific checkpoint (meaning that all steps after that will be re-executed) by passing a checkpoint_id value into the configuration for graph.invoke():
const config = {
configurable: {
thread_id: "1",
checkpoint_id: "0c62ca34-ac19-445d-bbb0-5b4984975b2a",
}
};
await graph.invoke(null, config);It’s possible to update a graph state by using graph.updateState(). If no checkpoint_id is specified, the latest state is updated. Note that the values passed into it are not explicit overwrites, but will be processed according to each channel configuration (meaning, the schema and how it is set up for updates).
Stores allow to store information across threads. We call the information stored here memories. Memories are namespaced by tuples ([value1, value2]) and have a key and a value:
import { MemoryStore } from "@langchain/langgraph";
import { v4 as uuidv4 } from "uuid";
const memoryStore = new MemoryStore();
const user_id = "1";
const namespace = [userId, "preferences"];
const memoryId = uuidv4();
const preference = { food_preference: "I like pizza" };
await memoryStore.put(namespace, memoryId, preference);
const preferences = await memoryStore.search(namespace);
preferences[preferences.length - 1];
// {
// value: { food_preference: 'I like pizza' },
// key: '07e0caf4-1631-47b7-b15f-65515d4c1843',
// namespace: ['1', 'preferences'],
// createdAt: '2024-10-02T17:22:31.590602+00:00',
// updatedAt: '2024-10-02T17:22:31.590605+00:00'
// }For retrieving memories we can use memoryStore.search(), which will return all memories in the namespace. If the memory store is configured with an embeddings model, we can perform semantic search on them:
import { OpenAIEmbeddings } from "@langchain/openai";
const store = new InMemoryStore({
index: {
embeddings: new OpenAIEmbeddings({ model: "text-embedding-3-small" }),
dims: 1536,
fields: ["food_preference", "$"], // Fields to embed
},
});
// Find memories about food preferences
// (This can be done after putting memories into the store)
const memories = await store.search(namespaceForMemory, {
query: "What does the user like to eat?",
limit: 3, // Return top 3 matches
});Nodes can always access the configuration provided and the store configured, as long as they use config and store in their parameters:
const callModel = async (
state: z.infer<typeof MessagesZodState>,
config: LangGraphRunnableConfig,
store: BaseStore
) => {
// Get the user id from the config
const userId = config.configurable?.user_id;
// Namespace the memory
const namespace = [userId, "preferences"];
// Search based on the most recent message
const memories = await store.search(namespace, {
query: state.messages[state.messages.length - 1].content,
limit: 3,
});
const info = memories.map((d) => d.value.memory).join("\n");
// ... Use memories in the model call
};Durable Execution
Wrapping up particular pieces of execution into tasks2 guarantees that they are checkpointed and don’t need to be recalculated when the graph resumes execution from an interruption. Nodes work too, but if a particular node gets too big, it might be useful to break down into tasks.
LangGraph has three durability modes:
exitsaves changes only when the graph execution completes (even if errored).asyncsaves changes for the status of the previous nodes as the next one executes. There’s a risk of inconsistency if the next node crashes the process.syncsaves changes between nodes but has an impact on performance.
Streaming
LangGraph allows for streaming so that live status can be displayed/accessed about the execution:
Stream modes:
values: Full value of the state after each stepupdates: Updates to the state after each stepcustom: Custom data from inside the nodesmessages: Tuple (LLM Token, metadata) from graph nodes where LLMs are invokeddebug: as much information as possible
for await (const chunk of await graph.stream(inputs, {
streamMode: ["updates", "custom"],
subgraphs: true,
})) {
console.log(chunk);
}Note that graph.stream() replaces graph.invoke() so it will also invoke the graph but yield the values to be streamed.
Also note that using subgraphs: true vs subgraphs: false (or not specified) will change the output of the streams. When subgraphs streaming are enabled, the chunks streamed will be a tuple of (namespace, chunk):
[[], {'node1': {'foo': 'hi! foo'}}]
[['node2:dfddc4ba-c3c5-6887-5012-a243b5b377c2'], {'subgraphNode1': {'bar': 'bar'}}]
[['node2:dfddc4ba-c3c5-6887-5012-a243b5b377c2'], {'subgraphNode2': {'foo': 'hi! foobar'}}]
[[], {'node2': {'foo': 'hi! foobar'}}]
Custom value streaming allows us to generate our own data from inside nodes or tools:
const graph = new StateGraph(State)
.addNode("node", async (state, config) => {
// Use the writer to emit a custom key-value pair (e.g., progress update)
config.writer({ custom_key: "Generating custom data inside node" });
return { answer: "some data" };
})
.addEdge(START, "node")
.compile();Tool example:
const queryDatabase = tool(
async (input, config: LangGraphRunnableConfig) => {
// Use the writer to emit a custom key-value pair (e.g., progress update)
config.writer({ data: "Retrieved 0/100 records", type: "progress" });
// perform query
// Emit another custom key-value pair
config.writer({ data: "Retrieved 100/100 records", type: "progress" });
return "some-answer";
},
{
name: "query_database",
description: "Query the database.",
schema: z.object({
query: z.string().describe("The query to execute."),
}),
}
);Interrupts
Interrupts allow to pause graph execution and wait for external input before continuing. The configured persistence is used to store the graph state.
import { interrupt } from "@langchain/langgraph";
async function approvalNode(state: State) {
// Pause and ask for approval
const approved = interrupt("Do you approve this action?");
// Command({ resume: ... }) provides the value returned into this variable
return { approved };
}After an interrupt, the graph can be invoked with a specific command to allow it to continue:
import { Command } from "@langchain/langgraph";
// Initial run - hits the interrupt and pauses
// thread_id is the durable pointer back to the saved checkpoint
const config = { configurable: { thread_id: "thread-1" } };
const result = await graph.invoke({ input: "data" }, config);
// Check what was interrupted
// __interrupt__ mirrors every payload you passed to interrupt()
console.log(result.__interrupt__);
// [{ value: 'Do you approve this action?', ... }]
// Resume with the human's response
// Command({ resume }) returns that value from interrupt() in the node
await graph.invoke(new Command({ resume: true }), config);The value passed under Command.resume is the return value of the interrupt call. Note that the node will run again, including the code before the interrupt.
Interrupts can be called as many times as necessary:
import { interrupt } from "@langchain/langgraph";
function getAgeNode(state: State) {
let prompt = "What is your age?";
while (true) {
const answer = interrupt(prompt);
// Validate the input
if (typeof answer === "number" && answer > 0) {
// Valid input - continue
return { age: answer };
} else {
// Invalid input - ask again with a more specific prompt
prompt = `'${answer}' is not a valid age. Please enter a positive number.`;
}
}
}Interrupt internals
Error handling: The mechanism of interrupt() is to throw a particular type of exception that LangGraph handles, so it’s important to not wrap it in try/catch structures, or if done, only catch the specific types of errors that we want to process.
Value matching: the way LangGraph provides values to the calls to interrupt (after the external inputs have been given) is index-based, so each execution of the node should go through the same list of interrupts in the same order. Conditional calling or re-ordering of the calls would create unexpected behaviour.
Contents: Interrupt values should be json-serializable, when invoking the interrupt and when providing result values into it.
Node idempotency: Because LangGraph has to call the node again (this time with interrupt returning a value) any code before it will be re-invoked. If there are side effects, they should be idempotent to prevent unexpected changes. This applies to subgraphs as well (either executed or sub-called from a node).
Interrupts for debugging
It is possible to add quick interrupts for debugging state in a particular graph. This can be done either at compile time or at run time. These are only recommended for debugging and not for live usage. The graph can be resumed by invoking it with the value of null for resume.
At compile time:
const graph = builder.compile({
interruptBefore: ["node_a"],
interruptAfter: ["node_b", "node_c"],
checkpointer,
});
const config = {...};
// Run the graph until the breakpoint
await graph.invoke(inputs, config);# [!code highlight]
await graph.invoke(null, config); # [!code highlight]At run time:
// Run the graph until the breakpoint
graph.invoke(inputs, {
interruptBefore: ["node_a"],
interruptAfter: ["node_b", "node_c"],
configurable: {...}
});
// Resume the graph
await graph.invoke(null, config);Memory
Because LLMs have a context limit, LangGraph provides solutions to it through the use of short-term memory. There are different approaches:
Trim Messages
Truncate the first (or last) messages until the token count approaches the specified limit.
import { trimMessages } from "@langchain/core/messages";
const callModel = async (state: z.infer<typeof MessagesZodState>) => {
const messages = trimMessages(state.messages, {
strategy: "last",
maxTokens: 128,
startOn: "human",
endOn: ["human", "tool"],
});
const response = await model.invoke(messages);
return { messages: [response] };
};Delete messages
This just deletes a message from the graph state. When doing so, make sure that the resulting message history still makes sense, so be careful about which messages you are deleting.
import { RemoveMessage } from "@langchain/core/messages";
const deleteMessages = (state) => {
const messages = state.messages;
if (messages.length > 2) {
// remove the earliest two messages
return {
messages: messages
.slice(0, 2)
.map((m) => new RemoveMessage({ id: m.id })),
};
}
};Summarize messages
A common approach is to keep a summary of the conversation so far as context that can be reused. LangChain does not provide any particular tool to do so, so instead it can be done by invoking the models to do such work:
import { RemoveMessage, HumanMessage } from "@langchain/core/messages";
const summarizeConversation = async (state: z.infer<typeof State>) => {
// First, we get any existing summary
const summary = state.summary || "";
// Create our summarization prompt
let summaryMessage: string;
if (summary) {
// A summary already exists
summaryMessage =
`This is a summary of the conversation to date: ${summary}\n\n` +
"Extend the summary by taking into account the new messages above:";
} else {
summaryMessage = "Create a summary of the conversation above:";
}
// Add prompt to our history
const messages = [
...state.messages,
new HumanMessage({ content: summaryMessage })
];
const response = await model.invoke(messages);
// Delete all but the 2 most recent messages
const deleteMessages = state.messages
.slice(0, -2)
.map(m => new RemoveMessage({ id: m.id }));
return {
summary: response.content,
messages: deleteMessages
};
};Subgraphs
Graphs can also be used in other graphs. This can be useful for reusing behaviour, or have multi-agent systems without complexity exploding, or even distribute development. All that needs to be respected is the schemas of the subgraphs at the points of communication.
Subgraphs don’t need to have checkpointers specified, but rather they are propagated from the parent graph. They can be specified, however, so that the subgraph has its own memory (useful for multi-agent systems).
Invoking subgraph from inside a node
const builder = new StateGraph(State)
.addNode("node1", async (state) => {
const subgraphOutput = await subgraph.invoke({ bar: state.foo });
return { foo: subgraphOutput.bar };
})
.addEdge(START, "node1");Any of the existing techniques and methods for invoking graphs can be used here.
Including subgraph as a node
// Subgraph
const subgraphBuilder = new StateGraph(State)
.addNode("subgraphNode1", (state) => {
return { foo: "hi! " + state.foo };
})
.addEdge(START, "subgraphNode1");
const subgraph = subgraphBuilder.compile();
// Parent graph
const builder = new StateGraph(State)
.addNode("node1", subgraph)
.addEdge(START, "node1");Notice that in this case, the states schema need to match (or at least, the parent graph state needs to be a superset of the subgraph state).
Project Structure
This is the recommended project structure for LangGraph projects:
my-app/
├── src # all project code lies within here
│ ├── utils # optional utilities for your graph
│ │ ├── tools.ts # tools for your graph
│ │ ├── nodes.ts # node functions for your graph
│ │ └── state.ts # state definition of your graph
│ └── agent.ts # code for constructing your graph
├── package.json # package dependencies
├── .env # environment variables
└── langgraph.json # configuration file for LangGraph
The langgraph.json configuration file is mostly used for deployments. More information here.
Studio
LangGraph has a free-to-use LangGraph Studio. It does require a LangSmith API Key however (currently free).
Quick features:
- See the graph in a visual manner
- Invoke graph and see results
- Interact with it, testing changes (will not be persisted)
- Set interrupts
- Graph view, chat view
- Fork, edit state
- Auto-reloading (when code is modified)
Testing
Testing can be done through vitest, where basically we invoke the graph and check the results:
import { test, expect } from 'vitest';
import {
StateGraph,
START,
END,
MemorySaver,
} from '@langchain/langgraph';
import { z } from "zod/v4";
const State = z.object({
my_key: z.string(),
});
const createGraph = () => {
return new StateGraph(State)
.addNode('node1', (state) => ({ my_key: 'hello from node1' }))
.addNode('node2', (state) => ({ my_key: 'hello from node2' }))
.addEdge(START, 'node1')
.addEdge('node1', 'node2')
.addEdge('node2', END);
};
test('basic agent execution', async () => {
const uncompiledGraph = createGraph();
const checkpointer = new MemorySaver();
const compiledGraph = uncompiledGraph.compile({ checkpointer });
const result = await compiledGraph.invoke(
{ my_key: 'initial_value' },
{ configurable: { thread_id: '1' } }
);
expect(result.my_key).toBe('hello from node2');
});Alternatively, individual nodes can be tested if invoked independently:
test('individual node execution', async () => {
const uncompiledGraph = createGraph();
// Will be ignored in this example
const checkpointer = new MemorySaver();
const compiledGraph = uncompiledGraph.compile({ checkpointer });
// Only invoke node 1
const result = await compiledGraph.nodes['node1'].invoke(
{ my_key: 'initial_value' },
);
expect(result.my_key).toBe('hello from node1');
});Agent Chat UI
LangGraph also provides an agent chat UI that can be used to expose a running agent.
# Create a new Agent Chat UI project
npx create-agent-chat-app --project-name my-chat-ui
cd my-chat-ui
# Install dependencies and start
pnpm install
pnpm dev
# Open it up in browser and use the tool