LoRA (Low Rank Adaptation) is a technique for minimizing the impact of fine tuning models.
Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times.1
Aside from the benefits in training speed and performance, LoRA makes it possible to deploy “weights as modules”, for a larger model that’s fine-tuned to be more accurate for specific tasks.
A traditional fine-tunning approach will update weights and record the difference in those weights (). Instead, LoRA looks to decompose the model weights, using the intrinsinc rank hypothesis, which states that not all weights are as important.
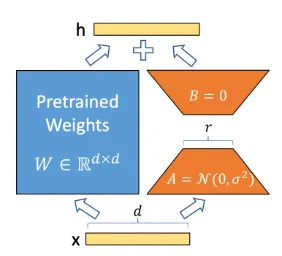
A full model is expressed by its weights (), which fine-tunning decomposes in the original pre-trained weights and the deltas found in their fine tuned weights (). At this point, the fine tuned weights has the same dimensions than the original model, but it could be very well decomposed into two matrices, , and , such that . If we consider to have dimensions , then we cannot choose these values, but we can choose a value and define the size of the new matrices such that .
Finally, is initialized to a random Gaussian, and is initialized to zero, such that , making no changes to the original model. Then, we freeze and just train on .